In this post, I describe how to create exclusive and shared locks that are faster and in some cases more reliable than the locks built into the .NET framework (particularly the Monitor and ReaderWriterLockSlim classes). I also help quantify when you should and should not replace exclusive locks with shared locks and briefly describe some schemes for performing thread-safe reads and writes without any locks at all. While the article refers to the .NET Framework, the techniques are generally applicable.
- Rationale
- Basic Techniques for Creating Locks
- Creating a Spin Lock
- Creating an Exclusive Lock that Waits
- An Upgradable Reader/Writer Lock
- Improving the Locks
- Lock-free Reads (and Writes)
- Lessons Learned
Rationale
In a lot of my code, I have data structures, usually caches, that are read from at least 95% of the time they're used and only occasionally written to. It bothered me to use exclusive locks, forcing all reading threads to serialize, just because once in a while a thread would want to write. I wanted to use the ReaderWriterLockSlim class to allow concurrent readers, but most of the time I don't know at the point when I enter the lock whether I want to just read or also write. For example:
enter the lock
read from the data structure
if the structure needs updating:
compute the change
update the data structure
exit the lock
If you enter a ReaderWriterLockSlim using the EnterReadLock method, you can't upgrade it to a write lock, and if you enter it using EnterUpgradeableReadLock method, then you again force all threads to serialize, because only one thread can enter the lock in upgradable mode. (The reason is that otherwise two reader threads could try to upgrade to a write lock, and they would both deadlock waiting for the other to exit the lock.) If you want to let reader threads share the lock, then you need to exit the lock and reenter it:
enter the lock in read (shared) mode
read from the data structure
if the structure needs updating:
compute the change
exit the lock
enter the lock in write (exclusive) mode
update the data structure
exit the lock
The problem with this is that often the change you're making depends on the data that you read from the data structure previously, and once you exit the lock you have no guarantee that you're making the right change anymore because another thread may have snuck in and modified the data first. You could have the write lock redo all the checks that you did in the read lock, but that means doing the work twice (and more complex code) when you need to write. So in most cases I just used an exclusive lock (the C# lock statement, which internally uses the Monitor class). Recently, however, I was flipping through the book CLR via C# by Jeffrey Richter, in which he mentions creating the Wintellect Power Threading Library, which is a closed-source library that contains his own reader/writer lock (among other things). I tried it out, and it's not very good. For one thing, it seems to deadlock in many cases, so it's untrustworthy. It's also pretty slow compared to ReaderWriterLockSlim, for instance, and doesn't allow upgrading at all, but it gave me the idea to create my own reader/writer lock to replace ReaderWriterLockSlim, which would allow any read lock to be upgraded to a write lock.
Basic Techniques for Creating Locks
The key point to keep in mind when creating a lock is that the lock state has to (appear to) change atomically. Users of the lock must see the lock as either held or not held and never in an inconsistent state, and the lock itself must never be confused if the lock state is changed by another thread. (Jeffrey Richter's Power Threading Library deadlocks precisely because it fails at this task, apparently due to some fundamental design flaws.) This can be done internally by actually changing the lock state atomically or by blocking other threads while you're changing the state. I'll describe both approaches.Updating lock state atomically
To update lock state atomically, there are two basic options. First, you can block while updating the lock state. To do this, you would use a fast exclusive lock. It may seem to defeat the purpose (or at least to be silly) to have one lock invoke another lock, but it's a viable approach in some situations — especially if the lock has complex state. The other option is to actually update the lock state atomically. This restricts you to packing all of the lock state into a single value no larger than the CPU can update with a single instruction, usually 64 bits. (This isn't a restriction in general, since the value could be a reference to an arbitrarily large object, but since we want to avoid allocating new objects on the heap during lock operations we'll limit ourselves to single integers.) A lock needs more than atomic reads and writes to its state variable, however; it needs atomic decision-making based on that state. (This is why Jeffrey Richter's Power Threading Library fails.)Since it should be obvious in general how to protect your lock state with an internal exclusive lock, I'll avoid discussing it further until later, when we've developed a lock complex enough to potentially warrant blocking internally. So let's look at how you can make decisions atomically. The key is the Interlocked.CompareExchange method. It has several overrides, but all of them have this signature: T CompareExchange(ref T location, T value, T comparand) for some type T. What the method does is simple: if the value at the given location is equal to comparand, it sets it to value. In either case, it then returns the original value from the given location. To put it another way, if CompareExchange returns comparand, then it assigned value to the location. Otherwise, it did not make the assignment. The important thing about the method is that it does the entire operation atomically. (On the x86 architecture, it no doubt does this using the CMPXCHG and CMPXCHG8B instructions.) To make atomic decisions with it you'll want to use code of the following general form (or its equivalent):
// T should be a type that is guaranteed to be read and written atomically in C# (e.g. int)
T state, newState;
do
{
state = lockState; // read the lock state atomically. (use Interlocked.Read if atomicity is not guaranteed by C#)
newState = ComputeNewState(state); // compute the new lock state
} while(Interlocked.CompareExchange(ref lockState, newState, state) != state);
In the example, if CompareExchange returns state, then the lock was in the same state as when we computed the new state, so the decisions we made are still valid, the state was updated, and the while loop will exit. Otherwise, if CompareExchange doesn't return state, then the state was changed by another thread, the decisions we made may no longer be valid, the state was not changed, and the while loop will restart so that we can examine the new state we're in. (Note that even if the while loop exits, it's possible that another thread changed the lock state and then changed it back while we were computing the new state, but if lockState contains the entire lock state then our decisions are still valid. To put it technically, the sequence of events would still be a valid linearization.) With this, we have enough information to build a simple (if unrealistic) lock.
Creating a Spin Lock
struct BadSpinLock
{
public void Enter()
{
while(Interlocked.CompareExchange(ref state, 1, 0) != 0) { }
}
public void Exit()
{
state = 0;
}
int state; // equals 0 if the lock is free and 1 if it's held
}
The Enter method loops until it atomically changes the state from zero to one, and the Exit method simply sets it back to zero. The Exit method doesn't need to use CompareExchange because a simple assignment to an int is guaranteed to be atomic and it doesn't need to make any decisions based on the lock state. Also note that the lock is nonrecursive: it doesn't allow the same thread to enter the lock twice. Both recursive and nonrecursive locks have their pros and cons. Recursive locks are more flexible, but nonrecursive locks can usually be released by a different thread from the one that acquired it (which is occasionally useful), and nonrecursive locks are generally faster, too. Also be aware of the fact that in this example the spin lock is a value type (i.e. a struct) and not a reference type (i.e. a class). As a result, you should avoid copying it or declaring it readonly. Since the spin lock is most commonly used for performance-critical locking scenarios, performance is improved by eliminating the memory allocation and additional indirection associated with reference types, but it could just as well be a reference type if you prefer.
This is a bad lock, though. There are many reasons why, including the fact that it doesn't do any error checking and doesn't assist the .NET runtime in maintaining AppDomain stability (see the Improving reliability section below for more details), but the most important reason is that the Enter method loops too tightly. If the lock is held for a substantial length of time, waiting threads may consume 100% CPU time. Also, on a single-core machine, there's no point in spinning while waiting for the lock to be released, since the thread that is holding the lock is not running and cannot release it. (While single-core CPUs are rare these days, single-core virtual machines are not. And anyway, it's good to be backwards-compatible.) We can make a small change to the spin lock to improve it:
// a better spin lock
public void Enter()
{
int spinCount = 0;
while(Interlocked.CompareExchange(ref state, 1, 0) != 0) SpinWait(spinCount++);
}
static void SpinWait(int spinCount)
{
if(spinCount < 10 && MultiProcessor) Thread.SpinWait(20*(spinCount+1));
else if(spinCount < 15) Thread.Sleep(0); // or use Thread.Yield() in .NET 4
else Thread.Sleep(1);
}
static readonly bool MultiProcessor = Environment.ProcessorCount > 1;
The result is a spin lock that's quite fast — about twice as fast as locking with a Monitor (or the C# lock statement). (It can be further sped up slightly by breaking the Enter method into two methods: Enter, which does if(Interlocked.CompareExchange(ref state, 1, 0) != 0) EnterSpin(); and EnterSpin, a private method that uses a do/while loop to perform the spin. This allows the compiler to inline the Enter method, and it's effective because much of the time the lock should not need to spin.) Spin locks are very effective when the lock will only be held for a very short length of time, but otherwise they are likely to consume CPU time unnecessarily.
Creating an Exclusive Lock that Waits
Usually, we want a thread that is waiting for a lock to go to sleep and not be awakened until the lock is available. This way, the operating system doesn't have to repeatedly schedule and switch to a thread that's doing no useful work. Let's create a new lock that does this.
sealed class SimpleExclusiveLock : IDisposable
{
public void Dispose()
{
semaphore.Close();
}
public void Enter()
{
while(true)
{
int state = lockState;
if((state & OwnedFlag) == 0) // if the lock is not owned...
{
// try to acquire it. if we succeed, then we're done
if(Interlocked.CompareExchange(ref lockState, state | OwnedFlag, state) == state) return;
}
// the lock is owned, so try to add ourselves to the count of waiting threads
else if(Interlocked.CompareExchange(ref lockState, state + 1, state) == state)
{
semaphore.WaitOne(); // we succeeded in adding ourselves, so wait until we're awakened
}
}
}
public void Exit()
{
// throw an exception if Exit() is called when the lock is not held
if((lockState & OwnedFlag) == 0) throw new SynchronizationLockException();
// we want to free the lock by clearing the owned flag. if the result is not zero, then
// another thread is waiting, and we'll release it, so we'll subtract one from the wait count
int state, freeState;
do
{
state = lockState;
freeState = state & ~OwnedFlag;
}
while(Interlocked.CompareExchange(ref lockState, freeState == 0 ? 0 : freeState - 1, state) != state);
if(freeState != 0) semaphore.Release(); // if other threads are waiting, release one of them
}
const int OwnedFlag = unchecked((int)0x80000000);
int lockState; // the high bit is set if the lock is held. the lower 31 bits hold the number of threads waiting
readonly Semaphore semaphore = new Semaphore(0, int.MaxValue);
}
This lock performs an efficient wait using a semaphore if it can't be acquired immediately. While waiting, a thread uses no CPU time. When the lock is exited, one of the waiting threads will be awakened. This allows a large number of threads to efficiently wait on the lock, unlike the spin lock, where each thread would be consuming CPU time polling the lock state. Also note how we've combined multiple pieces of information — the owned flag and the wait count — into a single integer. By squeezing the entire lock state into a single value, we can update it atomically using CompareExchange. Finally, note that like the spin lock above, this lock is non-recursive and does not keep track of which thread owns the lock, allowing it to be acquired on one thread and released on another thread. To keep track of the thread that owns the lock, you would need to store the ManagedThreadId somewhere. It would be possible to pack it into lockState by making lockState a 64-bit value, but that's unnecessary. The owner thread ID is an example of lock state that is not necessary for making decisions about how to transition the lock from one state to another. Therefore, it does not have to be read and written atomically along with the rest of the lock state, and can simply be considered part of the information protected by the exclusive lock. It would suffice to make the following changes:
public void Enter()
{
...
// try to acquire it. if we succeed, then we're done
if(Interlocked.CompareExchange(ref lockState, state | OwnedFlag, state) == state)
{
ownerId = Thread.CurrentThread.ManagedThreadId;
return;
}
...
}
public void Exit()
{
// throw an exception if Exit() is called when the lock is not held by this thread
if(Thread.CurrentThread.ManagedThreadId != ownerId) throw new SynchronizationLockException();
ownerId = -1;
...
}
int ownerId = -1;
This is a bit of a diversion, but I'll mention that the standard semaphores, wait events, and other such objects aren't the fastest way to wait. It's possible to build a slimmer, faster semaphore using the Wait and Pulse methods of the Monitor class. I won't describe those methods in detail (see their documentation or send me an email), but I'll give an example of a faster semaphore that we can use to build better locks:
sealed class FastSemaphore
{
public void Release()
{
lock(this)
{
if(count == uint.MaxValue) throw new InvalidOperationException();
count++;
Monitor.Pulse(this);
}
}
public void Release(uint count)
{
if(count != 0)
{
lock(this)
{
this.count += count;
if(this.count < count) // if it overflowed, undo the addition and throw an exception
{
this.count -= count;
throw new InvalidOperationException();
}
if(count == 1) Monitor.Pulse(this);
else Monitor.PulseAll(this);
}
}
}
public void Wait()
{
lock(this)
{
while(count == 0) Monitor.Wait(this);
count--;
}
}
uint count;
}
If you expose the semaphore publicly, you may want to define another object to lock rather than simply using the this pointer — otherwise somebody could lock the semaphore and confuse its internal logic — but for our purposes this is fine. We can swap the .NET Semaphore with this one in our SimpleExclusiveLock, and then the lock will be faster and no longer needs to implement IDisposable.
An Upgradable Reader/Writer Lock
Now that we have some of the pieces in place, let's return to our original goal of developing an upgradable reader/writer lock to replace ReaderWriterLockSlim. We need the following data in our lock state: 1) a Boolean indicating whether the lock is owned by a writer, 2) a Boolean indicating whether the lock is reserved for a writer, 3) the number of readers that own the lock, 4) the number of writer threads waiting, and 5) the number of reader threads waiting. Let's first develop the EnterRead and ExitRead methods, along with the supporting infrastructure.Reading
public sealed class UpgradableReadWriteLock
{
public void EnterRead()
{
while(true)
{
int state = lockState;
if((uint)state < (uint)ReaderMask) // if it's free or owned by a reader, and we're not currently at the reader limit...
{
if(Interlocked.CompareExchange(ref lockState, state + OneReader, state) == state) break; // try to join in
}
else if((state & ReaderWaitingMask) == ReaderWaitingMask) // otherwise, we need to wait. if there aren't any wait slots left...
{
Thread.Sleep(10); // massive contention. sleep while waiting for a slot
}
else if(Interlocked.CompareExchange(ref lockState, state + OneReaderWaiting, state) == state) // if we could get a wait slot...
{
readWait.Wait(); // wait until we're awakened
}
}
}
public void ExitRead()
{
if((lockState & ReaderMask) == 0) throw new SynchronizationLockException();
int state, newState;
do
{
// if there are other readers, just subtract one reader. otherwise, if we're the only reader and there are no writers waiting, free
// the lock. otherwise, we'll wake up one of the waiting writers, so subtract one and reserve it for the writer. we must be careful
// to preserve the ReservedForWriter flag since it can be set by a writer before it decides to wait
state = lockState;
newState = (state & ReaderMask) != OneReader ? state - OneReader :
(state & WriterWaitingMask) == 0 ? state & ReservedForWriter :
(state | ReservedForWriter) - (OneReader+OneWriterWaiting);
} while(Interlocked.CompareExchange(ref lockState, newState, state) != state);
if((state & ReaderMask) == OneReader) ReleaseWaitingThreads(state); // if we were the last reader, release waiting threads
}
void ReleaseWaitingThreads(int state)
{
// if any writers were waiting, release one of them. otherwise, if any readers were waiting, release all of them
if((state & WriterWaitingMask) != 0) writeWait.Release();
else if((state & ReaderWaitingMask) != 0) readWait.Release((uint)(state & ReaderWaitingMask));
}
const int OwnedByWriter = unchecked((int)0x80000000), ReservedForWriter = 0x40000000;
const int WriterWaitingMask = 0x3FC00000, ReaderMask = 0x3FF800, ReaderWaitingMask = 0x7FF;
const int OneWriterWaiting = 1<<22, OneReader = 1<<11, OneReaderWaiting = 1;
// the high bit is set if the lock is owned by a writer. the next bit is set if the lock is reserved for a writer. the next 8 bits are
// the number of threads waiting to write. the next 11 bits are the number of threads reading. the low 11 bits are the number of
// threads waiting to read. this lets us easily check if the lock is free for reading by comparing it to the read mask
int lockState;
readonly FastSemaphore readWait = new FastSemaphore(), writeWait = new FastSemaphore();
}
You should be able to follow this code given the methods we've developed previously. Of note is the way we've packed all the data we need into a single integer. The lock supports up to 2047 concurrent read threads and an unlimited number of threads waiting, despite only having space for 255 waiting writers and 2047 waiting readers within the state variable. (Any additional waiting threads will slowly spin while waiting to be added to the waiting thread count.) Also, by placing the write-related fields in higher bits than the reader count, we can see whether the lock is available for reading simply by comparing it to ReaderMask, since setting any of the write-related fields will cause it to be greater than ReadMask (when we do an unsigned comparison). Also of interest is the way we encapsulate multiple changes to the state variable into a single operation. For instance, if we want to set the ReservedForWriter bit, subtract one reader, and subtract one waiting writer, we can use the expression state + (ReservedForWriter-OneReader-OneWriterWaiting). We place parentheses around the three constants so that they will be converted into a single constant by the compiler, effectively state + constant. This kind of cleverness only works when we know that the additions and subtractions will not overflow or underflow any of the fields within the state value. For instance, the ReservedForWriter flag must be clear, and the number of readers and waiting writers must both be greater than zero. Otherwise, the lock state would be corrupted. Through careful design and coding, we can ensure that these assumptions are valid.
Regarding the overall design of the lock, it favors writers, which you can see from the fact that a thread wanting to read cannot enter the lock if any writer threads are waiting, even if the lock has not been reserved for them, and from the fact that it prefers to wake waiting writers over waiting readers. This is because a reader/writer lock is intended to be used in situations where many threads are reading concurrently and writes are rare. If the lock favored readers, a writer may never get a chance to enter the lock. Speaking of writers, let's add the EnterWrite and ExitWrite methods.
Writing
public void EnterWrite()
{
while(true)
{
int state = lockState, ownership = state & (OwnedByWriter|ReservedForWriter|ReaderMask);
if(ownership == 0 || ownership == ReservedForWriter) // if the lock is free or reserved for a writer...
{
// try to take it for ourselves
if(Interlocked.CompareExchange(ref lockState, state & ~ReservedForWriter | OwnedByWriter, state) == state) return;
}
else if((state & WriterWaitingMask) == WriterWaitingMask) // if we want to wait but there aren't any slots left...
{
Thread.Sleep(10); // massive contention. sleep while we wait for a slot
}
else if(Interlocked.CompareExchange(ref lockState, state + OneWriterWaiting, state) == state) // if we got a wait slot...
{
writeWait.Wait();
}
}
}
public void ExitWrite()
{
if((lockState & OwnedByWriter) == 0) throw new SynchronizationLockException();
int state, newState;
do
{
// if no writers are waiting, mark the lock as free. otherwise, subtract one waiter and reserve the lock for it
state = lockState;
newState = (state & WriterWaitingMask) == 0 ? 0 : state + unchecked(ReservedForWriter-OwnedByWriter-OneWriterWaiting);
} while(Interlocked.CompareExchange(ref lockState, newState, state) != state);
ReleaseWaitingThreads(state);
}
This is very straightforward, following the same approach as what we've seen so far. Now it's time to consider upgrading and downgrading.
Upgrading and downgrading
We want any thread with a read lock to be able to upgrade it into a write lock. In order for the upgrade to complete, all other readers must exit the lock. If two reader threads try to upgrade simultaneously, they could deadlock while waiting for each other to exit the read lock. ReaderWriterLockSlim disallows concurrent upgradable read threads for this reason, but we will allow it. Obviously a reader thread wanting to upgrade must still wait for other reader threads to exit the lock, but we prevent deadlock by doing the following: If a reader thread wanting to upgrade is the only reader, it will directly convert the lock from a read lock to a write lock. Otherwise, it will try to reserve the lock for itself. If it can reserve the lock, it will spin until all other readers have left and then take it in write mode. Otherwise, another upgrader has reserved it, so it will convert itself into a waiting writer and wait for a turn to write in the normal fashion. The caller of Upgrade will be informed of whether it was directly upgraded to a write lock (which should be the usual case) or whether it had to go onto the writer waiting list. If it was the former, the caller knows that any data it read previously is still valid. If it was the latter, the caller knows that data it read previously may be outdated and, if that would affect its calculations, it should reread the data. Here's the method:
public bool Upgrade()
{
if((lockState & ReaderMask) == 0) throw new SynchronizationLockException();
int spinCount = 0;
bool reserved = false;
while(true)
{
int state = lockState;
if((state & ReaderMask) == OneReader) // if we're the only reader...
{
// try to convert the lock to be owned by us in write mode
if(Interlocked.CompareExchange(ref lockState, state & ~(ReservedForWriter|ReaderMask) | OwnedByWriter, state) == state)
{
return true; // if we succeeded, then we're done and we were the first upgrader to do so
}
}
else if(reserved) // if the lock is reserved for us, spin until all the readers are gone
{
SpinWait(spinCount++);
}
else if((state & ReservedForWriter) == 0) // if the lock isn't reserved for anyone yet...
{
// try to reserve it for ourselves
reserved = (Interlocked.CompareExchange(ref lockState, state | ReservedForWriter, state) == state);
}
// there are other readers and the lock is already reserved for another upgrader, so convert ourself from
// a reader to a waiting writer. (otherwise, two readers trying to upgrade would deadlock.)
else if((state & WriterWaitingMask) == WriterWaitingMask) // if there aren't any slots left for waiting writers...
{
Thread.Sleep(10); // massive contention. sleep while we await one
}
else if(Interlocked.CompareExchange(ref lockState, state + (OneWriterWaiting-OneReader), state) == state)
{
writeWait.Wait(); // wait until we're awakened
EnterWrite(); // do the normal loop to enter write mode
return false; // return false because we weren't the first reader to upgrade the lock
}
}
}
Adding support for downgrading a lock from write mode to read mode is much easier, because we know we're the only writer.
public void Downgrade()
{
if((lockState & OwnedByWriter) == 0) throw new SynchronizationLockException();
int state;
do state = lockState;
while(Interlocked.CompareExchange(ref lockState, state + unchecked(OneReader-OwnedByWriter), state) != state);
}
Here's how you might use it.
bool writeMode = false;
rwLock.EnterRead();
try
{
recheck:
// read data structure here
if(structure needs update)
{
// compute change here
if(!writeMode)
{
bool mustRecheck = !rwLock.Upgrade();
writeMode = true;
if(mustRecheck) goto recheck;
}
// perform update here
}
}
finally
{
if(writeMode) rwLock.ExitWrite();
else rwLock.ExitRead();
}
If the change you computed wouldn't be affected by another thread upgrading (and updating the data structure) first, you can simplify the code a bit:
bool writeMode = false;
rwLock.EnterRead();
try
{
// read data structure here
if(structure needs update)
{
// compute change here
rwLock.Upgrade();
writeMode = true;
// perform update here
}
}
finally
{
if(writeMode) rwLock.ExitWrite();
else rwLock.ExitRead();
}
And that's it for a basic reader/writer lock! The upgrade scenario works, but the code needed is rather inelegant, so let's look at improving it.
Improving the Locks
To improve the lock further, we can make it more convenient, improve its performance, and make things more reliable in case of exceptional conditions (such as thread abortions). Let's look at those three items in turn.Improving lock convenience
One thing we can do for convenience is to make EnterRead and EnterWrite return IDisposable objects that call ExitRead and ExitWrite respectively. This enables syntax like the following:
using(rwLock.EnterRead())
{
// read data
}
Here's how you could do it:
public ReadReleaser EnterRead()
{
...
return new ReadReleaser(this);
}
// this structure is nested within UpgradableReadWriteLock
#region ReadReleaser
public struct ReadReleaser : IDisposable
{
internal ReadReleaser(UpgradableReadWriteLock owner)
{
this.owner = owner;
}
public void Dispose()
{
if(owner != null)
{
owner.ExitRead();
owner = null;
}
}
UpgradableReadWriteLock owner;
}
#endregion
You might wonder why we're returning a strongly-typed public struct rather than a generic IDisposable object, such as a private sealed class. The reason is twofold. First, we want to avoid allocating memory on the heap in the lock operations, for both performance and reliability reasons. We could try allocating the releaser object once in the lock constructor and simply having it call ExitRead whenever Dispose is called, but that would be a violation of the IDisposable interface, which specifies that the Dispose method must be idempotent — that is, calling it multiple times should have the same effect as calling it once. If there was only one releaser object, it couldn't easily keep track of whether Dispose had already been called in a particular context. It also wouldn't be good to make the struct private and have the method return IDisposable because that would require boxing the struct and allocating memory. Using a public struct allows us to avoid memory allocation while still obeying the IDisposable interface.
An analogous change could be made for EnterWrite. It would even be possible to have the releaser object keep track of whether the lock had been upgraded or downgraded, as in the following example.
public LockReleaser EnterRead()
{
...
return new LockReleaser(this, false);
}
public LockReleaser EnterWrite()
{
...
return new LockReleaser(this, true);
...
}
// this structure is nested within UpgradableReadWriteLock
#region LockReleaser
public struct LockReleaser : IDisposable
{
internal LockReleaser(UpgradableReadWriteLock owner, bool writeMode)
{
this.owner = owner;
this.writeMode = writeMode;
}
public bool Exclusive
{
get { return writeMode; }
}
public void Dispose()
{
if(owner != null)
{
if(writeMode) owner.ExitWrite();
else owner.ExitRead();
owner = null;
}
}
public void Downgrade()
{
AssertNotDisposed();
if(!writeMode) throw new SynchronizationLockException();
owner.Downgrade();
writeMode = false;
}
public bool Upgrade()
{
AssertNotDisposed();
if(writeMode) throw new SynchronizationLockException();
bool firstUpgrader = owner.Upgrade();
writeMode = true;
return firstUpgrader;
}
void AssertNotDisposed()
{
if(owner == null) throw new ObjectDisposedException(GetType().FullName);
}
UpgradableReadWriteLock owner;
bool writeMode;
}
#endregion
Then using the lock in an upgradable mode would be simpler:
using(var lockContext = rwLock.EnterRead())
{
recheck:
// read data structure here
if(structure needs update)
{
// compute change here
if(!lockContext.Exclusive && !lockContext.Upgrade()) goto recheck;
// perform update here
}
}
Or if rechecking the data structure is not necessary:
using(var lockContext = rwLock.EnterRead())
{
// read data structure here
if(structure needs update)
{
// compute change here
lockContext.Upgrade();
// perform update here
}
}
Improving lock performance
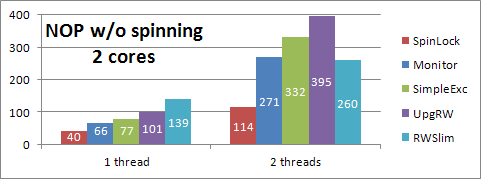 Fig. 1 – Initial bare lock performance (exclusive)
Fig. 1 – Initial bare lock performance (exclusive)
What happened? It's hard to be sure when dealing with locks because any attempt at gathering performance data (e.g. incrementing static variables to see how often locks are waiting, etc.) can substantially change the performance of the locks. For instance, simply adding waited++; after semaphore.Wait(); in SimpleExclusiveLock slows the lock performance with 2 threads from 332 ns to 520 ns! (The reason is that after one thread exits and wakes the other thread, there is a race to acquire the lock again. Incrementing the variable causes the awakened thread to lose the race much more often, making its awakening pointless.) Placing waited++; before the wait has a negligible effect. The program then reports that about one million waits occurred out of 80 million attempts to enter the lock, meaning that the locks have to wait only 1.25% of the time. Attempting to time the waits to see how much time they're costing us causes the number of waits to drop to only 24,000. So attempting to collect detailed statistics is not that easy and we'll mostly have to experiment.
We'll note first that both entering a wait and releasing a waiting thread require using Monitor (inside FastSemaphore), and Monitor is relatively expensive — even assuming the lock inside FastSemaphore is uncontended, we can expect our code to take an additional 66 ns every time we have to use it. So perhaps instead of immediately waiting when a lock is held, we can try spinning for a bit, like the SpinLock does. That helps. Spinning up to 5, 10, 15, 20, and 25 times (using the same spinning algorithm as the spin lock) improves the performance of the SimpleExclusiveLock from 332 ns to 293, 205, 204, 162, and 173 ns respectively. It seems that 20 spins is about the sweet spot, at least for 2 threads doing no work in a tight loop on my machine. Furthermore, it seems that the best performance comes from the region of the spinning between 15 and 20 iterations, which is when SpinWait switches to calling Thread.Sleep(1), so we can try skipping over the first 15 iterations and just calling Thread.Sleep(1) directly. That improves the performance further from 162 ns to 147 ns. Here's the change to the Enter method for SimpleExclusiveLock.
public void Enter()
{
int spinCount = 0;
while(true)
{
int state = lockState;
if((state & OwnedFlag) == 0) // if the lock is not owned...
{
...
}
else if(spinCount < 5)
{
Thread.Sleep(1);
spinCount++;
}
// the lock is owned, so try to add ourselves to the count of waiting threads
...
}
}
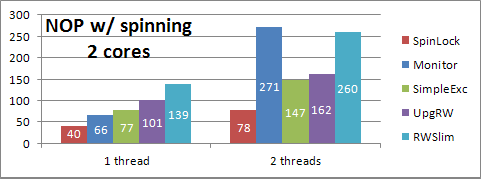 Fig. 2 – An improvement?
Fig. 2 – An improvement?
Unfortunately, at this point I made (and unmade) many small changes to the locks without saving detailed performance data before and after each change, so I can't illustrate the path I took towards optimizing the locks, although I can briefly describe it. The first thing I did was to write a test harness that would execute a series of tests against the various locks, with one through eight threads, on two different machines (one older two-core machine and one newer four-core machine). The tests encompassed exclusive locking, shared locking with reads, shared locking with reads and writes, and shared locking with reads and upgrades, using different sized work loads and different ratios of reads to writes. The test harness output the data in a format that I could directly paste into a spreadsheet. I'll list here some of the changes I ended up making to the locks:
public void EnterRead()
{
int spinCount = 5;
...
if((uint)state < (uint)ReaderMask) // if it's free or owned by a reader, and we're not currently at the reader limit...
{
if(Interlocked.CompareExchange(ref lockState, state + OneReader, state) == state) break; // try to join in
BriefWait();
}
else if(spinCount < MaxSpins)
{
SpinWait(spinCount++);
}
...
}
public void Upgrade()
{
...
else if(reserved)
{
BriefWait();
}
...
}
void EnterWriteCore()
{
int spinCount = 5;
...
else if(spinCount < MaxSpins)
{
SpinWait(spinCount++);
}
...
}
static void BriefWait()
{
if(MultiProcessor) Thread.SpinWait(1);
else Thread.Sleep(0); // or use Thread.Yield() in .NET 4
dummy++;
}
static void SpinWait(int spinCount)
{
if(spinCount < 10 && MultiProcessor) Thread.SpinWait(20*(spinCount+1));
else if(spinCount < 15) Thread.Sleep(0); // or use Thread.Yield() in .NET 4
else Thread.Sleep(1);
dummy++;
}
// for whatever reason, incrementing this variable at spin points greatly improves lock
// performance in some cases. perhaps it has some effect on the processor cache. i donno.
static int dummy;
Here in EnterRead I added a call to BriefWait if we missed our chance to join the set of readers on a lock. Intuitively this doesn't seem like it would help anything, but for whatever reason it does in some cases. Second, I changed the spinning back to using SpinWait. While Thread.Sleep(1) seems to work well for exclusive locks, it doesn't seem like the best choice for shared locks. However, I initialized the spin count to 5 so it would begin sleeping sooner. Finally, I added an increment to a static dummy variable in the spin methods. It made a big difference in a couple tight locking loops and didn't noticeably decrease performance anywhere. (I discovered it while attempting to collect performance data in some static variables.)
In Upgrade I changed it from using SpinWait to using BriefWait. Putting the thread to sleep during upgrade turned out to be a bad idea. In EnterWriteCore(), I changed it back to using SpinWait as well. Even though EnterWrite takes an exclusive lock, Thread.Sleep(1) doesn't work well when there are other threads taking shared locks simultaneously, and that's the intended use case for a reader/writer lock. You may also want to try playing with the SpinWait and BriefWait methods. Minor changes to those methods can have big effects on lock performance, and I'm sure I haven't found optimal spin methods.
Creating a lock that blocks internally
After creating an upgradable reader/writer lock using Interlocked.CompareExchange, I implemented a second version that used an internal spin lock to ensure atomic updates of lock state. It turned out to be inferior in most cases (although it was better in a few), so I won't describe it in detail, but I'll present the core implementation below. To a large degree, it's simpler than the version that uses CompareExchange. It doesn't have to pack all of its state into a single value, nor does it need so many loops. Despite being a bit slower, the difference may not be significant, it may be faster in your particular case, and it may be easier to write and debug, so it's an approach worth considering.
sealed class UpgradableReadWriteLock
{
public void Downgrade()
{
if((state & Writer) == 0) throw new SynchronizationLockException();
EnterLock(ref spinLock);
state -= Writer-1;
spinLock = 0;
Thread.EndCriticalRegion();
}
public void EnterRead()
{
int spinCount = 0;
while(true)
{
EnterLock(ref spinLock);
if(state < ReaderMask)
{
state++;
spinLock = 0;
return;
}
else if(spinCount < MaxSpins)
{
spinLock = 0;
SpinWait(spinCount++);
}
else
{
readersWaiting++;
hasWaiter = true;
spinLock = 0;
spinCount = 0;
readWait.Wait();
}
}
}
public void EnterWrite()
{
Thread.BeginCriticalRegion();
EnterWriteCore(false);
}
public void ExitRead()
{
if((state & ReaderMask) == 0) throw new SynchronizationLockException();
EnterLock(ref spinLock);
state--;
ReleaseWaitingThreadsIfAny();
}
public void ExitWrite()
{
if((state & Writer) == 0) throw new SynchronizationLockException();
EnterLock(ref spinLock);
state &= ~Writer;
ReleaseWaitingThreadsIfAny();
Thread.EndCriticalRegion();
}
public bool Upgrade()
{
if((state & ReaderMask) == 0) throw new SynchronizationLockException();
Thread.BeginCriticalRegion();
int spinCount = 0;
bool reserved = false;
while(true)
{
EnterLock(ref spinLock);
if((state & ReaderMask) == 1) // if we're the only reader...
{
state += Writer-1; // convert the lock to be owned by us in write mode
if(reserved && writersWaiting == 0) state &= ~WriterWaiting;
spinLock = 0;
return true;
}
else if(reserved)
{
spinLock = 0;
if(spinCount < 100) ThreadUtility.BriefWait();
else ThreadUtility.Spin(spinCount++);
}
else if((state & WriterWaiting) == 0)
{
state |= WriterWaiting;
spinLock = 0;
reserved = true;
ThreadUtility.BriefWait();
}
else
{
writersWaiting++;
state = (state-1) | WriterWaiting;
hasWaiter = true;
spinLock = 0;
writeWait.Wait();
EnterWriteCore(true); // we're a writer now, so do the normal loop to enter write mode
return false; // return false because we may not have been the first writer to take the lock
}
}
}
void EnterWriteCore(bool clearWaitBit)
{
int spinCount = 0;
EnterLock(ref spinLock);
if(clearWaitBit && writersWaiting == 0) state &= ~WriterWaiting;
while(true)
{
if((state & ~WriterWaiting) == 0) // if the lock is unowned
{
state |= Writer; // take it for ourselves
spinLock = 0;
return;
}
else if(spinCount < MaxSpins)
{
spinLock = 0;
SpinWait(++spinCount);
EnterLock(ref spinLock);
}
else
{
writersWaiting++;
state |= WriterWaiting;
hasWaiter = true;
spinLock = 0;
spinCount = 0;
writeWait.Wait();
EnterLock(ref spinLock);
if(writersWaiting == 0) state &= ~WriterWaiting;
}
}
}
void ReleaseWaitingThreads()
{
if(writersWaiting != 0)
{
if((state & ReaderMask) == 0)
{
if(--writersWaiting == 0 && readersWaiting == 0) hasWaiter = false;
spinLock = 0;
writeWait.Release();
return;
}
}
else if(readersWaiting != 0) // otherwise, if any readers were waiting, release all of them
{
uint count = readersWaiting;
hasWaiter = false;
readersWaiting = 0;
spinLock = 0;
readWait.Release(count);
return;
}
spinLock = 0;
}
void ReleaseWaitingThreadsIfAny()
{
if(hasWaiter) ReleaseWaitingThreads();
else spinLock = 0;
}
const uint Writer = 0x80000000, WriterWaiting = 0x40000000, ReaderMask = 0x3FFFFFFF, MaxReaders = ReaderMask;
const int MaxSpins = 20;
int spinLock;
// high bit is set if a writer owns the lock. the next bit is set if a writer is waiting. the low 30 bits are the number of readers
uint state;
uint readersWaiting, writersWaiting;
readonly FastSemaphore readWait = new FastSemaphore(), writeWait = new FastSemaphore();
bool hasWaiter;
static void EnterLock(ref int spinLock)
{
if(Interlocked.CompareExchange(ref spinLock, 1, 0) != 0) EnterLockSpin(ref spinLock);
}
static void EnterLockSpin(ref int spinLock)
{
bool multiProcessor = Environment.ProcessorCount > 1;
int spinCount = 0;
do
{
spinCount++;
if(spinCount <= 10 && multiProcessor) Thread.SpinWait(20*spinCount);
else if(spinCount <= 15) Thread.Sleep(0);
else Thread.Sleep(1);
} while(Interlocked.CompareExchange(ref spinLock, 1, 0) != 0);
}
static void SpinWait(int spinCount)
{
if(spinCount < 5 && Environment.ProcessorCount > 1) Thread.SpinWait(20 * spinCount);
else if(spinCount < MaxSpins-3) Thread.Sleep(0);
else Thread.Sleep(1);
}
}
Performance results
Here are the final results from my efforts. Click the thumbnails to enlarge the graphs, which show the lock performance on two different machines.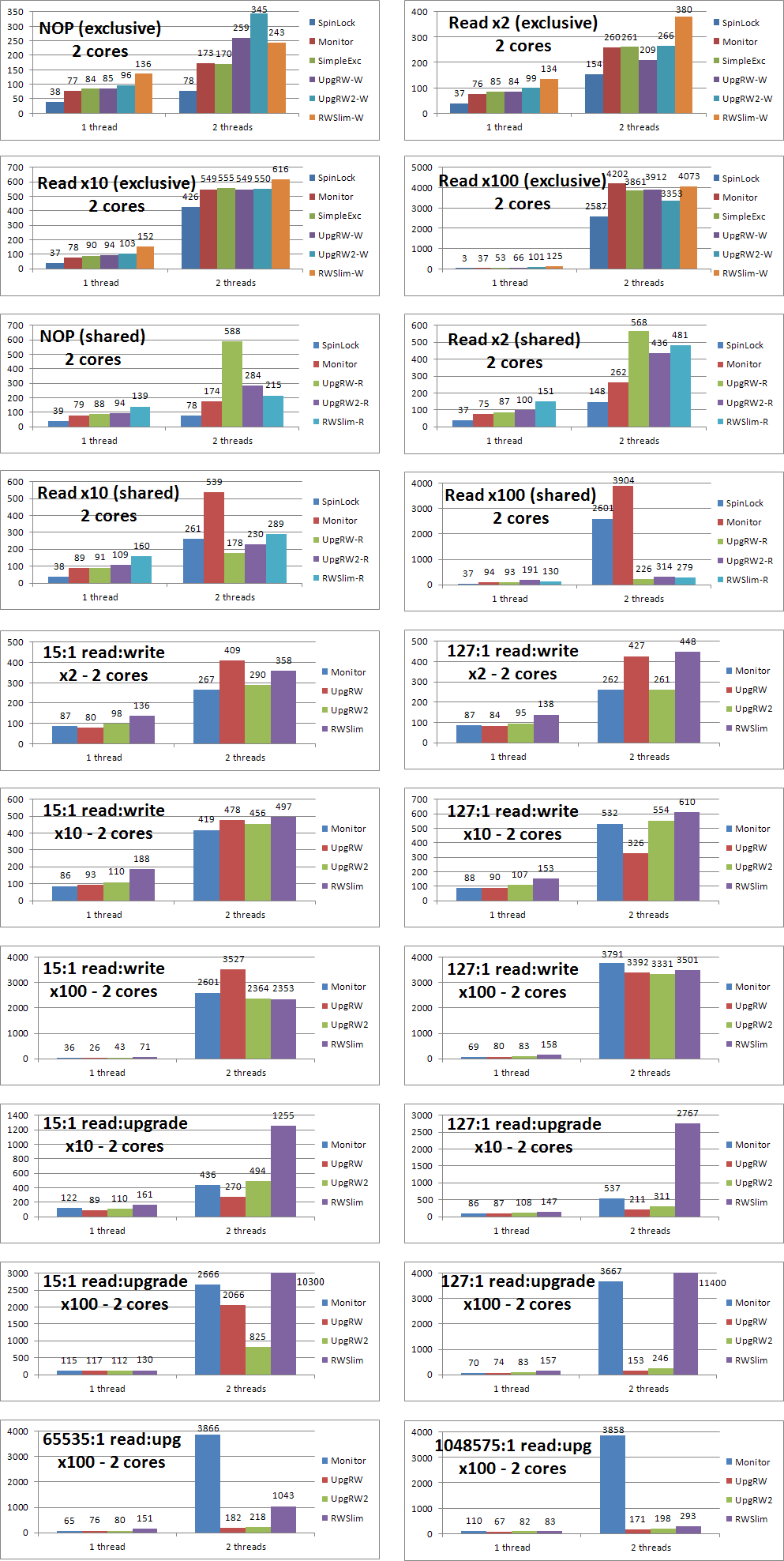
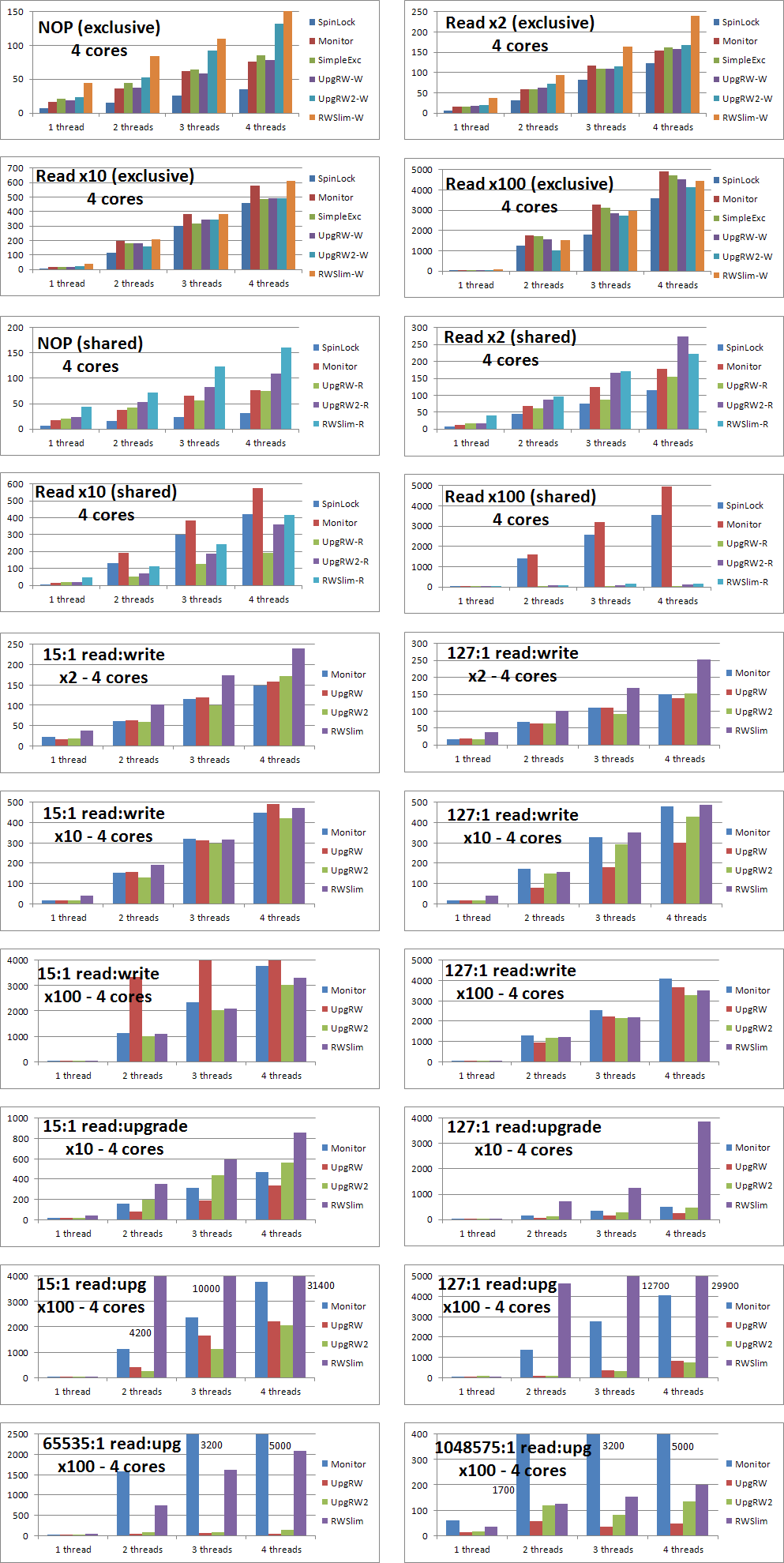
Some notes about the results: First, the two-core and four-core results can't be compared directly because the machines are of different speeds, bus widths (32-bit vs. 64-bit), etc., but the proportions are pretty consistent. I didn't want to spend the many hours it would take to compute the results to a high degree of precision, so don't take small numerical differences to be meaningful unless they're consistent. Also, SpinLock refers to the spin lock developed in this article, not the SpinLock class built into .NET 4.
The first four graphs show exclusive lock performance with different amounts of work within the lock. The SpinLock, Monitor, SimpleExclusiveLock (labeled "SimpleExc"), UpgradableReadWriteLock (using CompareExchange, labeled "UpgRW"), UpgradableReadWriteLock (using an internal spin lock, labeled "UpgRW2"), and ReaderWriterLockSlim ("RWSlim") classes are profiled. The reader/writer locks were all used in exclusive mode (e.g. EnterWrite). In all cases, SpinLock is the fastest by a wide margin, and Monitor and SimpleExclusiveLock are about the same. The reader/writer locks are generally slower than or roughly comparable to the purely exclusive locks, especially when the amount of work done within the lock is small. In general, UpgRW beats UpgRW2 by a significant margin, but in one case the opposite is true. The overall conclusion is that for exclusive locks, you should use Monitor, unless you really need the performance of the SpinLock — the benefit is greater when the work inside the lock is less — or the cross-thread ability of the SimpleExclusiveLock.
The next four graphs demonstrate shared lock performance with different amounts of work within the lock. SpinLock and Monitor are included as a reference, and to help identify the point at which it becomes beneficial to switch from an exclusive lock to a reader/writer lock. With small amounts of work (i.e. a few hash table reads or less), the exclusive locks are faster. With an amount of work equivalent to about 10 hash table reads, shared locks are a little bit faster (especially UpgRW), but may not be worth the extra code complexity. With 100 hash table reads, the benefit of using shared locks can be massive. Note, however, that this only applies when there is lock contention. It's not enough to have multiple threads accessing a resource. The threads have to be inside the lock at the same time. If that's not the case, then it's equivalent to the "1 thread" results in the graphs, in which Monitor is always faster than the reader/writer locks. The upshot is that even though reader/writer locks are potentially much faster, they are usually slower because most locks do not see enough contention, so you should test in your particular scenario before switching to a reader/writer lock. Additionally, I'll note that UpgRW is always much faster than UpgRW2 in this case, and both are almost always faster than RWSlim.
The next six graphs demonstrate a mix of reads and writes (i.e. EnterRead and EnterWrite) using the three reader/writer locks, with Monitor included as a reference. The graphs are divided by the amount of work done (2, 10, and 100 hash table reads) and the ratio of reads to writes (15:1 and 127:1). Although the results are somewhat anomalous, they don't show any real benefit of using a shared lock over an exclusive lock. There seems to be no benefit at a ratio of 15 reads per write. At 127:1, UpgRW is faster than Monitor, but the other locks are roughly the same. Later testing found no benefit to using a shared lock (Monitor was twice as fast) for 2 hash reads at any read:write ratio. For larger work loads at a ratio of 1023:1, UpgRW was clearly much faster than Monitor, but the other locks were not. At 65535:1, all reader/writer locks were faster than Monitor. In most cases, UpgRW was much faster than RWSlim. Note, however, that it's not the actual ratio that matters but the degree to which writes interrupt reads, which depends largely on the amount of contention, which in turn depends on various factors. In the test, the operations were executed in a tight loop, but in other situations the ratio at which a shared lock is faster may be different, so you should test before switching to a reader/writer lock.
The final six graphs demonstrate a mix of reads and upgrades (i.e. EnterRead/Upgrade for UpgradableReadWriteLock and EnterUpgradeableReadLock/EnterWriteLock for ReaderWriterLockSlim), with Monitor included as a reference. About 10% of the work done in the upgrade path was done inside the read lock before upgrading it, and the remaining 90% was with the write lock held. The graphs are divided in much the same way as the read/write test above, but the results are rather different. The performance of UpgradableReadWriteLock is better than before, beating Monitor even at 15:1 and being massively faster at higher ratios and/or larger work loads. Most surprising is the performance of RWSlim, which is awful — in most cases several times slower than Monitor, in every case much slower than UpgRW (75 times slower in some cases!), and not showing a huge benefit until a ratio of a million to one. Furthermore, ReaderWriterLockSlim actually deadlocked fairly consistently on a few of the upgrade tests, especially with 4 or more threads. (I'll also note that I was using .NET 3.5, although the same problem likely exists in .NET 4.) The usual caveats about contention apply, but it's clear that my read/upgrade pattern is an improvement over both the read/write and read/upgrade patterns available with ReaderWriterLockSlim.
Overall, it's clear that Monitor is the best general-purpose lock, SpinLock is the fastest exclusive lock, and UpgRW is the best reader/writer lock (although UpgRW2 beats it in a few cases). I don't claim that my own locks are bug-free, and I certainly take no responsibility for anybody else's implementation of the ideas on this page, but according to these tests, the UpgradableReadWriteLock in my AdamMil.net library is both faster and, in the upgrade case, more reliable than ReaderWriterLockSlim. On the other hand, my locks do less error-checking, so code written using them may be more difficult to debug. That said, there's nothing preventing you from taking these ideas and adding additional error-checking, perhaps surrounded by #if DEBUG to avoid any runtime penalty in release builds.
Improving reliability
Because locks are intended to protect shared resources, they have special responsibilities. For instance, if a thread is aborted while holding an exclusive lock, the shared state the lock was protecting is likely to be left in an inconsistent (i.e. corrupt) state and other threads may deadlock while trying to acquire the lock, which will never be released. A lock has the responsibility to inform the .NET runtime of those possibilities so the runtime can take appropriate measures when a thread needs to be aborted while holding the lock. This is done by calling Thread.BeginCriticalRegion and Thread.EndCriticalRegion. BeginCriticalRegion should be called at the beginning of Enter, EnterWrite, and Upgrade, and EndCriticalRegion should be called at the end of Exit, ExitWrite, and Downgrade. For example:
public void Enter()
{
Thread.BeginCriticalRegion();
int spinCount = 0;
...
}
public void Exit()
{
...
if(freeState != 0) semaphore.Release(); // if other threads are waiting, release one of them
Thread.EndCriticalRegion();
}
public void Downgrade()
{
...
while(Interlocked.CompareExchange(ref lockState, state + unchecked(OneReader-OwnedByWriter), state) != state);
Thread.EndCriticalRegion();
}
public void EnterWrite()
{
Thread.BeginCriticalRegion();
EnterWriteCore();
}
public void ExitWrite()
{
...
ReleaseWaitingThreads(state);
Thread.EndCriticalRegion();
}
public void Upgrade()
{
if((lockState & ReaderMask) == 0) throw new SynchronizationLockException();
Thread.BeginCriticalRegion();
...
else if(Interlocked.CompareExchange(ref lockState, state + (OneWriterWaiting-OneReader), state) == state)
{
writeWait.Wait(); // wait until we're awoken
EnterWriteCore(); // we're a writer now, so do the normal loop to enter write mode
return false; // return false because we may not have been the first writer to take the lock
}
...
}
It may be worthwhile to place read locks within a critical region as well. Although threads aborted while holding a read lock should not corrupt any shared state, they may still cause writer threads to deadlock. Note that EnterWrite was refactored into EnterWrite and EnterWriteCore, and Upgrade was changed to call EnterWriteCore.
The second reliability issue is also simple. The runtime uses the HostProtectionAttribute to restrict the use of synchronization primitives to code that is allowed to use them. You just need to decorate your lock classes with the following attribute:
[HostProtection(SecurityAction.LinkDemand, Synchronization=true, ExternalThreading=true)] public sealed class MyLock ...For more information on the reliability features of the .NET runtime, see this article.
Lock-free Reads (and Writes)
There's another, easy way to solve the concurrent reader / occasional writer problem, and it lets you avoid locking for readers entirely. It's not applicable in all situations, but in some cases it's very useful, especially when the data structure is small and reads are fast enough that the overhead of using a lock would easily double, triple, or quadruple the read time. The idea is to atomically replace the data structure with a new one, using either a lock or Interlocked.CompareExchange. (Usually a lock is better because it prevents writers from stepping on each other's toes.)
Dictionary<int,string> dict = new Dictionary<int,string>();
void Read()
{
// read from the dictionary as normal. no locks needed! note that the dictionary could
// be swapped with a new one at any point, so this only works with a single read unless
// the code is immune to problems that may result from reading both old and new data
}
void Write()
{
lock(dict)
{
Dictionary<int,string> newDict = new Dictionary<int,string>(dict); // copy the existing data
// modify newDict as required
dict = newDict; // reference assignment is atomic
}
}
If writers are rare enough and/or the data structure is small enough, this method can have excellent performance. In addition to this method for lock-free reads, there is a class of algorithms that give lock-free writes as well, called non-blocking algorithms. These typically make use of Interlocked.CompareExchange or a similar primitive to provide a data structure that can be updated by multiple threads in the same way our locks can. Because of this, however, their performance may not be better and may in fact be worse than well-written locking code. If you don't mind leaving the realm of portable code, though, you can potentially make some very fast data structures using machine code in certain places where atomic updates are desired. For example, a Bloom filter is a data structure that needs no locking and filling a Bloom filter is an embarrassingly parallel operation, but only if you can ensure that setting a bit in the Bloom filter is atomic. Without that guarantee, you must resort to expensive locking. I'm not aware of any high-level language that guarantees atomic bitwise ORs, but pretty much any CPU can perform a bitwise OR atomically if you use the right instructions. As a result, it's trivial to implement a lock-free Bloom filter if you use machine code to set the bits, but very difficult if you use only a general purpose programming language.
Another way to achieve lock-free code is to use per-thread data structures. If you have several threads working on the same operation, they could each accumulate their results into a per-thread data structure with no locking needed. Then you could simply combine the data at the end. As an example, if you had a Bloom filter that was not thread-safe, you could still fill it with many threads in a lock-free fashion by having each thread fill its own copy of the Bloom filter. Then at the end you'd do a bitwise OR on the Bloom filters to combine them. Unfortunately, in some case this greatly increases memory usage.
As a final comment, I'll mention that the .NET Hashtable class allows lock-free reads concurrent with a single writer, so if you don't mind losing type safety you can build fast caches around a Hashtable. Only writers need to lock, and only if there are multiple writers. (The Dictionary<K,V> class does not provide this guarantee.)
readonly Hashtable cache = new Hashtable();
public void Read()
{
// read from the cache. no lock needed!
// (but you have to prepare for the cache to change at any point)
}
public void Write()
{
lock(cache)
{
// update the cache
}
}
Lessons Learned
In most of my locking code (e.g. simply reading from caches), the work done within the lock is so fast that it's very unlikely for there to be any lock contention. In that case, it's counterproductive to use a reader/writer lock because the lock overhead must be paid every time the lock is entered, and since the overhead is much higher than a Monitor, it would greatly outweigh the rare savings from allowing multiple threads to enter the lock. An uncontended spin lock is faster than an uncontended Monitor, but the ungainly syntax is unlikely to be worth it unless you have several threads entering the lock in a tight loop, and in that case there may be more effective ways to optimize than trying to speed up the lock (such as using per-thread data as described above). In short, because most locks are held for a short period of time and are therefore uncontended, it's usually best to simply use a Monitor.The flip side of this is that reader/writer locks are most effective when the work done within the lock is time-consuming. In that case, the ability to parallelize threads can yield a large increase in throughput and responsiveness. However, that typically means that the overhead of entering the lock is insignificant compared to the time spent within the lock, which means that creating your own lock which executes a bit faster than the built-in locks is unlikely to be worth the risk of obscure bugs (even considering that ReaderWriterLockSlim appears to have its own obscure bugs in the upgrade path). Furthermore, writes have to be quite rare before the overhead of using a reader/writer lock is significantly better than a Monitor.
I'm not aware of any time-consuming tasks done within a lock in my own code, and even if I was, I'd be hesitant to use a reader/writer lock now without hard data showing that lock contention is an issue. I recommend not replacing simple locks with reader/writer locks unless the benefits are proven. So the whole exercise of creating my own reader/writer lock has been a largely useless task, but it was educational for me, and I hope for you too. :-)
Comments
If you use CompareExchange, then if the exchange fails you would need to loop, and what would you do in that case? Keep looping? If so, you'll burn CPU cycles. In some places, spinning is appropriate, but in other places, we want the thread to go to sleep...
However, I was surprised that you don't talk at all about memory barriers (half and full fences, operation reordering) - topics which are usually very much relevant for lock implementations.
So the question really is, are you sure that your implementations are indeed really correct?
Though I don't have a non-x86/x64 platform to test on, and though it's been 10 years since I wrote this, I believe my locks only depend on the Interlocked.CompareExchange method working as advertised. And I expect that it does work as advertised on every platform.